
“Agentic identity monitoring” splits immediately once you ask: where is the agent actually running?
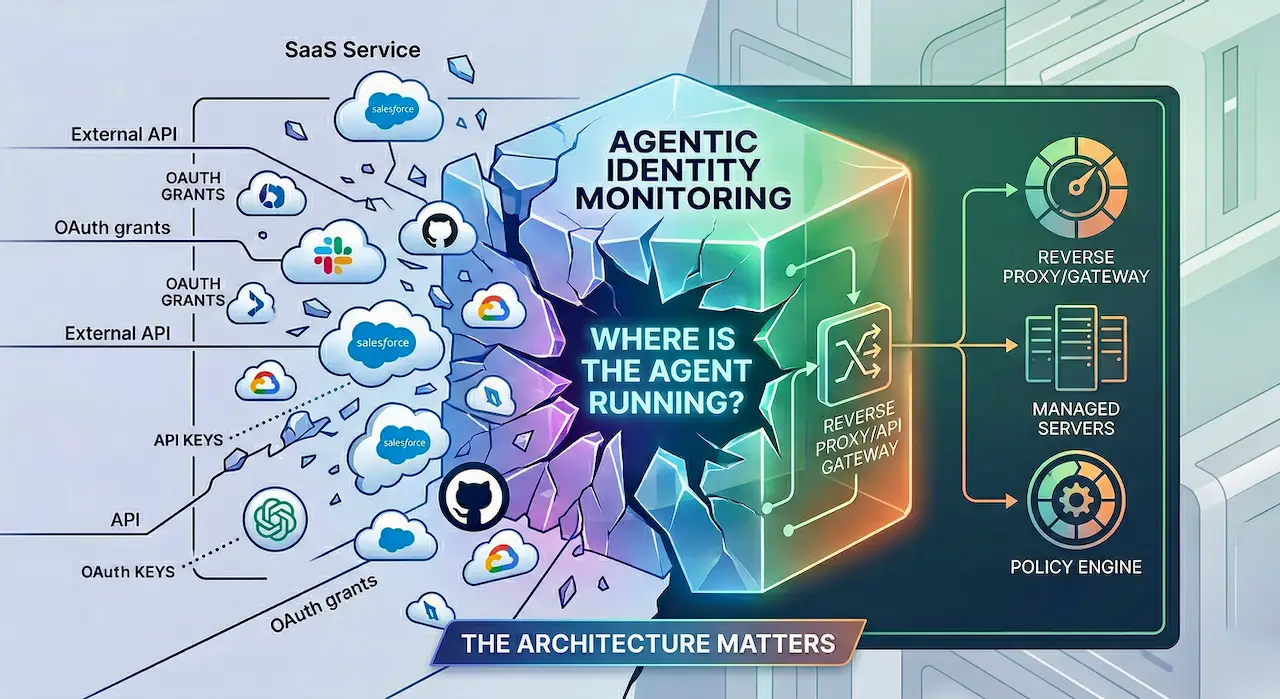
The phrase agentic identity monitoring is already becoming too vague to be useful.
At minimum, it is collapsing two very different security problems into one label.
The first is SaaS-to-SaaS visibility: one cloud service connects to another, often through OAuth, sometimes through API keys or service credentials, and the enterprise is usually not in the runtime path.
The second is enterprise-hosted MCP or internal API control: the agent is calling tools, servers, or APIs that sit behind infrastructure the enterprise actually owns, which means the enterprise can often sit inline and make real-time decisions.
Those are not small implementation details. They are different architectures, different telemetry models, different enforcement models, and different limits on what can and cannot ever be seen.
If you do not separate them, you end up talking about “agentic security” as though it were one product category. It is not.
1) SaaS-to-SaaS: broad visibility outside your perimeter, but mostly reconstructive
Start with the common case: one SaaS service connects to another.
ChatGPT connects to HubSpot. Claude connects to Google Drive. Zapier connects to Jira. A user stands up a personal n8n instance and connects it to Salesforce. A workflow platform gets access to Slack, Notion, GitHub, and a ticketing system.
The key fact is architectural: your enterprise usually does not own the runtime path between those services.
That means you are usually not inspecting live traffic between SaaS A and SaaS B. You are reconstructing reality from whatever telemetry those systems choose to expose: audit logs, admin events, OAuth grants, app consent records, scope inventories, connected-app listings, webhook registrations, API key metadata, and whatever other fragments you can collect.
That is useful. Often extremely useful. But it has hard limits.
Once OAuth has succeeded and the connection exists, you usually cannot directly see:
- the live request and response payloads between the two SaaS platforms
- the exact object-level data being pulled at runtime
- every action one service takes inside the other
- the full sequence of downstream operations after token issuance
- whether the integration is currently active, idle, or being abused, unless the vendor exposes that telemetry
In some cases, you cannot even reliably know the connection exists at all.
That last point matters more than most people admit.
A lot of the market talks as though “SaaS-to-SaaS” means “OAuth app with a consent screen.” Sometimes it does. But not everything is OAuth.
Many SaaS products let users or admins generate API keys, personal access tokens, bot tokens, service credentials, or webhook secrets. Those credentials can then be dropped into a VM, a container, a GitHub Action, a personal n8n deployment, a Zapier workflow, a cron job, or whatever automation stack someone wants to use.
Now you still have a SaaS-to-SaaS connection in effect. It is just not represented as a clean OAuth relationship that your identity team can easily enumerate.
And in some cases, the credential is not meaningfully tied to an active user session at all. A person generated it once. Maybe they are no longer using the app. Maybe they no longer even have a paid seat. Maybe they changed roles months ago. The key keeps living in some worker, script, or automation pipeline and continues to operate independently.
That creates a nearly invisible class of connection.
Your IdP will not see the runtime usage of that credential. Your network stack will not see SaaS-to-SaaS API traffic occurring entirely in third-party clouds. Your endpoint telemetry is irrelevant if the automation is running on infrastructure you do not manage. And if the SaaS vendor does not provide good API-key inventory, app connection telemetry, or audit records, you may not even be able to prove the relationship exists from any single source.
That is why the first problem is fundamentally a discovery and mapping problem.
You cannot enforce against what you do not know exists.
Once you do have visibility, enforcement often exists here too. It is just a different kind of enforcement than inline proxy control. It usually means taking action on the objects you discovered: disabling the account, revoking the OAuth grant, deleting the API key, rotating the secret, removing admin consent, reducing scopes, disabling the connected app, or changing the policy that allowed the connection in the first place.
That can be powerful. In many environments, it is the only realistic way to shut down risky cross-SaaS access.
But the order matters:
first discover the connection, then enforce on the credential, grant, app, or account.
If the connection is invisible, none of those actions are available.
That is why breadth matters so much in this model. No single system has the full picture. The IdP sees one piece. The source SaaS sees another. The destination SaaS sees another. Admin consoles, audit APIs, billing state, ownership data, groups, service accounts, and HR context all tell partial truths.
So the right strategy is to integrate as broadly as possible, build as complete an identity and access graph as possible, and cross-reference as much as possible.
Because this is what you are really trying to answer:
- Which SaaS systems are trusted by which other SaaS systems?
- Which grants are over-scoped?
- Which service credentials are orphaned?
- Which automations are running outside approved platforms?
- Which integrations still function even though the original human owner no longer should matter?
- Which external trust relationships exist that nobody explicitly approved?
This is why SaaS-to-SaaS security is closer to SaaS identity posture than classic inline security.
It gives you visibility into what happens outside your perimeter. That matters enormously, especially in organizations where the real control plane has already sprawled into dozens or hundreds of SaaS platforms.
But it does not replace perimeter control. It cannot, because that is not where it lives.
2) Enterprise-hosted MCP and internal APIs: this is where inline control actually exists
Now contrast that with an agent calling an enterprise-hosted MCP server, internal tool gateway, or internal API.
This is a different security architecture.
Here the enterprise owns the reverse proxy, API gateway, auth layer, token broker, policy engine, approval flow, logging pipeline, and often the downstream tool surface too. The traffic crosses infrastructure the enterprise actually controls.
That changes what is possible.
In this model, you can often see the caller identity, the device or workload identity, the presented token, the requested tool or method, the parameters, the policy decision, the approval event, the token exchange into downstream credentials, and the response metadata. You can decide in real time whether the call is allowed, transformed, narrowed, delayed for approval, or blocked outright.
This is where terms like inline enforcement actually mean something.
You can require step-up approval before an agent calls a sensitive tool. You can exchange a broad upstream token for a narrowly scoped downstream token. You can gate access on device posture, network zone, workload identity, user role, or time of day. You can apply DLP-style inspection to requests and responses. You can restrict which models or agents are allowed to call which internal actions. You can record and audit the exact boundary crossing that matters.
This is the place for reverse proxies, token exchanges, secure access gateways, and a modern return of DLP-style controls for agent access.
But this model also has hard limits, and they are different ones.
Owning the MCP server does not make the rest of the world visible.
If a user separately created a HubSpot API key and dropped it into a personal automation outside your infrastructure, your internal gateway sees nothing.
If a local desktop agent reads files, scrapes the screen, inspects browser content, or interacts with local processes before it ever calls your internal tool, your server-side gateway does not see those local actions. That is an endpoint problem.
If your managed internal service later hands data off to an external SaaS and that SaaS performs additional operations in its own cloud, you only see what crossed your boundary. You do not automatically see everything that happens after the handoff.
And if users or teams can bypass the gateway entirely, then your inline controls govern only the subset of traffic that voluntarily flows through the managed path.
So this model is stronger on prevention, but only for the paths you actually own.
It answers a different set of questions:
- Which internal tools can this agent call?
- Under which identity and under which policy?
- Was the request approved, denied, or narrowed?
- What data crossed the boundary?
- Which token was minted for which downstream action?
- What happened at the moment of access?
Those are first-class security controls. They are just not the same thing as discovering cross-SaaS relationships that were established elsewhere.
These are complements, not substitutes
This is the split people should be explicit about.
SaaS-to-SaaS visibility is about discovering and governing trust relationships that exist outside infrastructure you control. It is broad, reconstructive, and dependent on vendor telemetry and cross-system correlation. Once you find the connection, enforcement often exists there too: revoke the grant, delete the key, disable the account, reduce the scope. But first you have to know it exists.
Enterprise-hosted MCP and internal API control is about enforcing policy on traffic that crosses infrastructure you do control. It is narrower, more direct, and much stronger at real-time prevention.
One helps you understand what has already been wired together across clouds.The other helps you decide what you will allow through systems you own.
Which matters more depends on the organization.
If your environment is full of SaaS sprawl, shadow automations, user-generated API keys, disconnected business tooling, and services talking to each other outside central control, then the first problem is usually the larger blind spot. It gives broader coverage of real external exposure.
If your environment is tightly centralized—strict SAML, strong zero-trust controls on endpoints, well-managed gateways, token-brokered access paths, and meaningful agent activity forced through enterprise-controlled tool surfaces—then the second problem becomes the more important enforcement layer.
But they are not interchangeable.
One is primarily about finding and governing what exists outside your perimeter.The other is about enforcing what is allowed inside the paths you control.
Calling both “agentic identity monitoring” without saying which one you mean is not precision. It is branding.
The architecture is what matters.